抓取开心网粉丝信息
很多网页抓取工具一般只抓取表状信息,从而,这些工具一般将抓取结果用EXCEL表或者关系数据库表存储。MetaSeeker与之不同,可以抓取嵌套的树状信息,并用XML文件格式存储抓取结果。而网页上的内容本质上是用DOM树表示的,这样做数据映射关系很直接,表现出很强的抓取能力。一般来说,嵌套的树状结构数据如果需要存入关系数据库,则需要使用多个有关联的表,GooSeeker发布的MetaCorpora程序能够很灵活地将树状数据结构进行拆解并转存到MySQL关系数据库中。本文将讲解怎样定义树状整理箱(用于存储抓取结果的数据结构),将以抓取开心网的粉丝信息为例。抓取粉丝信息或者社交网络的好友关系有很多用途,例如,识别用户特征,发现意见领袖(e见领袖);又如,建立社交图谱,这些信息都可以用于建立舆情监测系统或者竞争情报系统。
本案例的抓取目标描述如下:
- 样本页面:http://www.kaixin001.com/home/?uid=84691607
- 主题:newbalance_kaixin_1
- 抓取目的
- 将关注新百伦品牌的粉丝抓取下来
注意:读者可以将本案例提到的信息结构(用于生成抓取规则的对目标网页结构进行描述的信息)加载到MetaStudio上,帮助理解本文内容。但是,如果目标网页的结构改变了,可能会影响到信息结构的有效性,可能加载不成功,请参照《修改失效的抓取规则》对信息结构进行修改。
1 定义树状整理箱
假设我们准备将下列结构的信息抓取下来:
- 粉丝数
- 访问数
- 粉丝列表:列表中有多个粉丝记录,每个记录具有下面的字段
- 粉丝页面
- 粉丝名
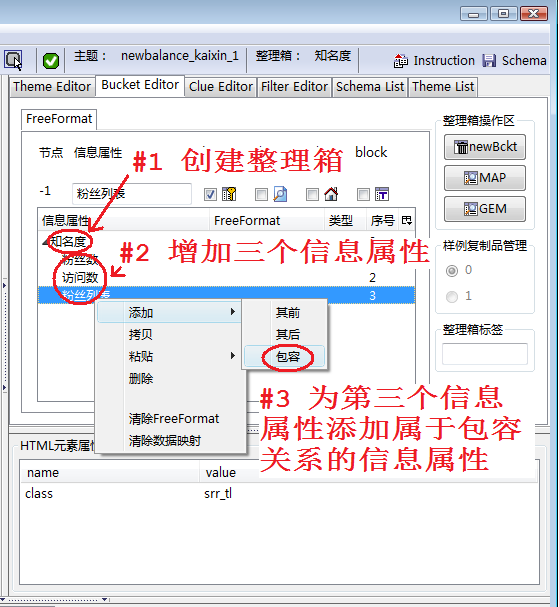
图1
图1显示创建整理箱的过程:
- 创建整理箱,起名“知名度”,则在整理箱编辑区增加了第一个容器节点。我们将整理箱中的含有下级信息属性(存储抓取结果的字段)的节点称为容器节点。
- 在节点“知名度”下添加三个信息属性
- 在第三个信息属性下再添加一个属于包容关系的信息属性,这样第三个节点就变成了内部容器节点,形成了树状结构。
2 定义抓取规则
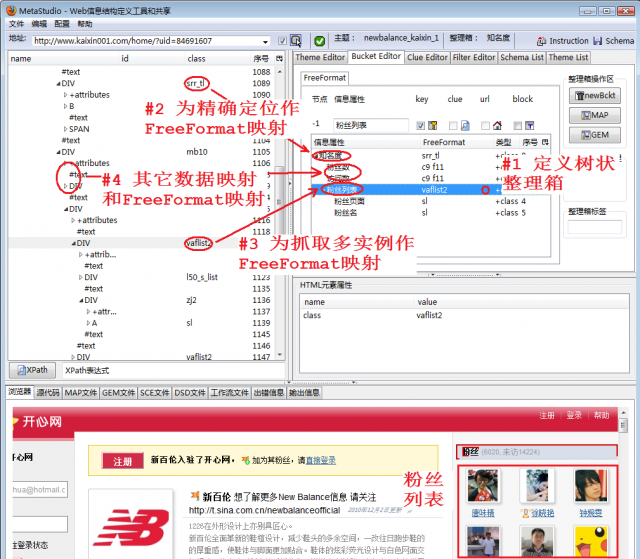
图2
将所有信息属性添加上后,通过数据映射和FreeFormat映射定义抓取规则,图2显示如下步骤:
- 观察定义的树状整理箱,其中“粉丝数”和“访问数”位于网页上的粉丝列表的表头,而“粉丝列表”里面存储12个粉丝的信息,每个粉丝的相关信息有“粉丝页面”和“粉丝名”,这样就形成了两层嵌套。
- 为了在网页上精确地将粉丝块定位出来,进行一次FreeFormat映射,详细说明参见《精确提取新蛋网商品价格信息》
- 为了抓取多个粉丝的信息,需要定义多实例抓取规则,我们使用FreeFormat映射方法,详细参见《抓取京东商城商品价格》;除此以外,也可以用样例复制品映射方法抓取多实例,详细参见《抓取当当百货价格》
- 为其它信息属性作数据映射和FreeFormat映射
定义完成后,上载到MetaSeeker服务器上,以便DataScraper随时随地使用这个抓取规则。
3 抓取结果

图3
图3显示抓取结果片断,为顶层容器节点只抓取到一个实例,而“粉丝列表”中有多个实例。
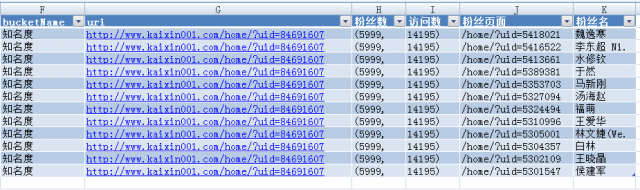
图4
图4显示用微软MS Excel打开抓取结果XML文件看到的内容,可以看到由于“粉丝列表”有多个实例,为了用二维表格显示数据,“粉丝数”和“访问数”每行都拷贝了一遍,造成数据冗余。如果将抓取结果导入MySQL关系数据库,最好消除数据冗余,即分解成两个表,可以通过外键关联在一起。如果使用MetaCorpora语料库管理系统导入数据库,既可以采用有冗余方式,也可以采用消除冗余方式,只要做相应配置即可。
- Login to post comments
粤ICP备11065265号-2

Comments
如何实现批量的抓取文中的信息
文中一个用户的粉丝数以及访问数和粉丝列表都抓取过了,如果实现批量的抓取很多用户的同样的信息?而不是一个一个的去抓取,谢谢了
先生成线索
具有相同网页模板的网址,都可以放在一个主题下抓取,在线版用户生成线索的方法有两个(不包括在MetaStudio上一个个上载,那样太慢)
1,在http://www.metacamp.cn/datastore/manageclue.htm 网页上,搜索到相应主题,有录入网址的界面,一个个录入
2,自己写一个网页,上面全部是要生成线索的网址,比如,在ul标签中用100个li标签存储100个网址,针对这个网页做一个主题,专门抓取这些网址,而且设置clue特性,就能在Clue Editor工作台上出现第二级主题名输入界面,这就定义了一个二级抓取,第二级的主题就是你先前定义的抓微博的主题