卓越网商品数据分级抓取
前面我们已经讲解了当当网和京东商城的抓取案例:
要部署商品比价系统或者竞争情报分析平台,显然还需要抓取更多网站的商品价格。本文讲解卓越网站的抓取方案。
同前两篇文章不同,本文重点讲解分级抓取方法,分成以下两级:
- 先抓取商品类别信息网页,在那个网页上抓取每个类别的类别名和网页的URL地址
- 进入每个类别的网页,在此抓取所有商品列表,重点抓取商品名和价格
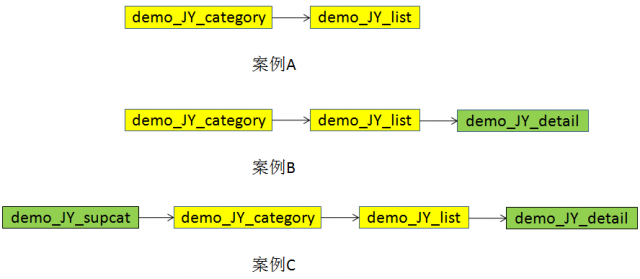
实际上还可以有第三步,进行第二步的时候,能够抓取到每个商品的详细信息网页的URL地址,如图1的案例B,在第三步,进入这个详细信息页,抓取更多商品信息,例如,详细规格说明、用户评论等等。
层级还可以向另外一个方向延伸,如图1C,先在一个类别汇聚网页上抓取所有类别的URL,例如,卓越网http://www.amazon.com.cn/gp/site-directory/ref=topnav_sad 就是这种网页。卓越网实际上将类别分成多级:大类别、小类别还有更小的类别。本文讲解案例A。
MetaSeeker可以抓取任何多级,因为MetaSeeker跟其他网站抓取软件不同,内部有一个完整的网络爬虫,也就是说采用了搜索引擎的技术,网络爬虫可以深入抓取任何多级。而且像搜索引擎那样,上级和下级的抓取在时间顺序上没有关联,下级可以在任何时候执行,这一点也跟很多网站抓取软件不同。这些特性赋予MetaSeeker强大的能力和很高的性能。
《手机游戏网站抓取规划》系列文章用大篇幅文字详细说明了分级抓取的规划和执行过程,本文重点用屏幕截图直观地说明这些过程。
下面我们以卓越网作为目标网站:
- 第一级:在大类网页上抓取商品小类别,目的是抓取小类别的网页URL
- 样本网页:http://www.amazon.com.cn/gp/site-directory/ref=topnav_sad
- 主题名:demo_JY_mobile_category
- 第二级:在商品列表网页上抓取所有商品的价格和其他数据。第一级抓取的URL能够访问到一个网页,网页上罗列了所有属于某个小类别的商品,本级的抓取目标就是这个商品列表。
- 样本网页:
- 主题名:demo_JY_mobile_list
注释1:用MetaStudio定义网站抓取规则时不用考虑顺序,但是,为了写作的方便,我们先定义第一级再定义第二级。
注释2:本文不再为每一步做截图,MetaStudio的详细操作步骤参看《抓取当当网百货价格》。
1 抓取商品类别
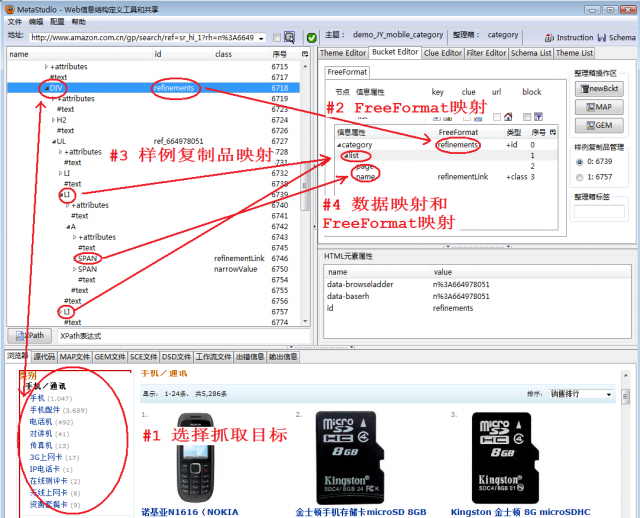
如图2,定义抓取商品类别的规则的步骤如下:
- 网页左侧的类别栏是本次抓取的目标,它对应DOM树上的DIV[@class='refinements']节点
- 将@class='refinements'作为FreeFormat标志映射给信息结构的顶层容器节点category,有关FreeFormat映射的详细过程参见《抓取京东商城价格》
- 在顶层容器节点下创建嵌套的容器节点list(参看下面的注释),并做样例复制品映射,有关样例复制品映射的详细过程参见《抓取当当百货价格》
- 在list容器中只有两个信息属性:page和name分别抓取网页URL和类别名,所以要进行数据映射和FreeFormat映射。
注释:本例创建了一个嵌套的容器,这不是必须的。创建容器节点category并将FreeFormat标志refinements映射给它的目的是:精确地在网页上将类别信息块定位出来,然后再在这个块内使用样例复制品规则抓取所有类别名和网址。
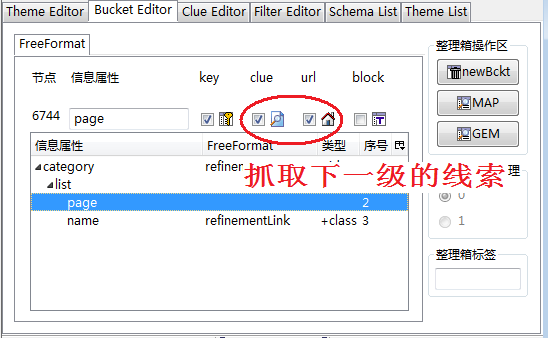
图3显示整理箱中的信息属性page的各种特性,可以看到勾选了clue和url,表示抓取到的URL网址不仅仅被当成普通数据对待,而且在这个网址基础上创建一条线索,引导网络爬虫抓取下一级数据。如果设定了这两个特性,在Clue Editor工作台上自动创建了一个Info类型的线索。
2 定义下一级线索
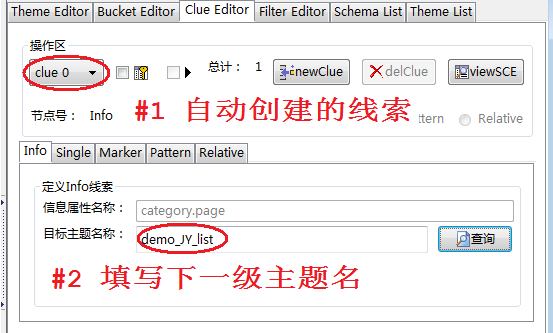
如图4,有如下步骤:
- 因为在Bucket Editor工作台上为信息属性page设定了clue和url特性,在Clue Editor工作台上会看到自动创建了一个编号为clue 0的线索,是Info类型,表示利用page字段的值创建一条线索
- 给下一级抓取主题起一个名字:demo_JY_list
至此,第一级的信息结构已经定义完成,参照《抓取当当网百货价格》上载信息结构和MetaStudio自动生成的网站抓取规则,DataScraper就可以随时随地对卓越网上的手机类别进行抓取了。
3 为下一级定义数据抓取规则
为了定义一个新的数据抓取规则,首先需要在MetaStudio上创建一个新的工作台(重新运行MetaStudio或者点击菜单文件-〉创建工作台),然后在新工作台上定义数据抓取规则和线索抓取规则。为了定义下一级数据抓取规则,当然可以采用这个操作过程。还有另外一种方式:假设我们定义完第一级抓取规则后,并没有立即定义第二级,而是运行了DataScraper,为第一级抓取数据,这样就为第二级抓取到了很多线索,此时,再用MetaStudio定义第二级抓取规则时,MetaStudio自动从这些线索中找一个样本网页,而不用手工输入样本网页的地址。
3.1 抓取第一级
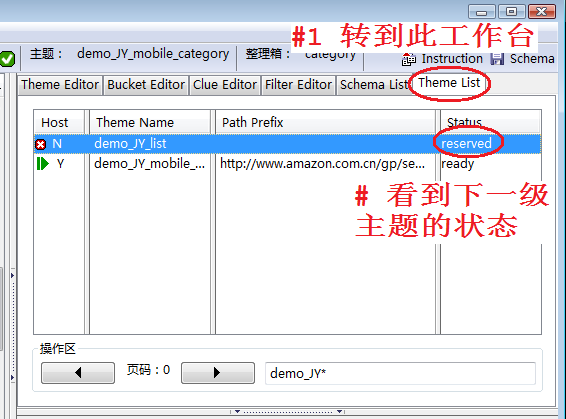
在没有执行抓取第一级数据之前,我们看一下当前的主题状态,如图5:
- 转到Theme List工作台,并输入查询条件demo_JY*
- 看到下一级主题的状态是reserved
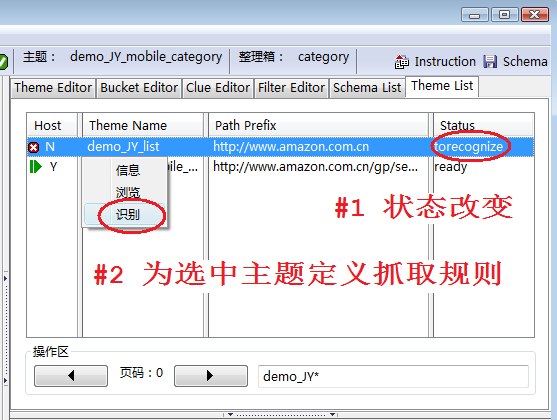
用DataScraper为主题demo_JY_mobile_category抓取完数据后,再在MetaStudio上看主题demo_JY_list的状态,如图6:
- 状态变成torecognize,表示已经为第二级主题抓取到了很多线索,但是还没有为它定义抓取规则。
- 在MetaStudio的Theme List工作台上选中这个主题,点击鼠标右键,弹出菜单,选择菜单项识别,开始为下一级主题定义信息结构。首先会弹出一个告警框,提示您当前工作台不空,是否要清空,确认后发现MetaStudio自动选择了一个样本页面并加载到内嵌浏览器中,而且重新刷新了DOM树,并清空了各个工作台。
3.2 定义第二级的抓取规则
同《抓取京东商城价格》一样,我们要抓取下面的数据:
- 商品名:商品名称
- 商品网页:显示商品详细信息的网页地址,这个地址有很多用处,例如,用做导航,以便执行下一级采集(图1案例B)。
- 市场价格:卓越给出的市面价格
- 卓越价格:卓越的优惠价
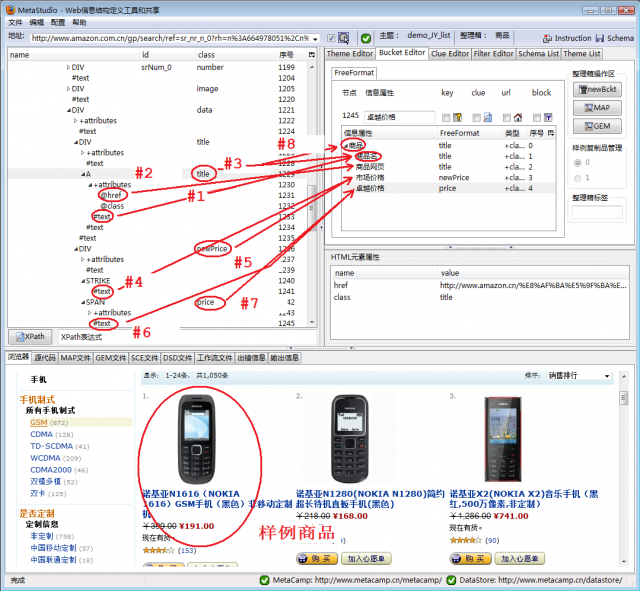
图7显示了数据映射和FreeFormat映射操作,有如下步骤:
- 将含有商品名的TEXT节点映射给信息属性商品名,这是数据映射
- 将含有商品详细信息页面网址的@href节点映射给信息属性商品网页,这也是数据映射
- 将@class='title'映射给信息属性商品名和商品网页,这是FreeFormat映射
- 将含有市面价格的TEXT节点映射给信息属性市场价格,这是数据映射
- 将@class='newPrice'映射给信息属性市场价格,这是FreeFormat映射
- 将含有卓越价格的TEXT节点映射给信息属性卓越价格,这是数据映射
- 将@class='price'节点映射给信息属性卓越价格,这是FreeFormat映射
- 最后,将@class='title'的节点映射给顶层容器节点商品,这是为了用FreeFormat方法抓取多实例,详细说明参见《抓取京东商城价格》。
点击MAP按钮查看生成的抓取规则,并点击TestThis测试抓取规则,发现只抓取了样例商品。这是因为卓越网页上有很多@id属性,每个商品都有唯一的@id,MetaStudio在缺省情况下优选@id作为FreeFormat标志,为了改变缺省行为,参看图8。
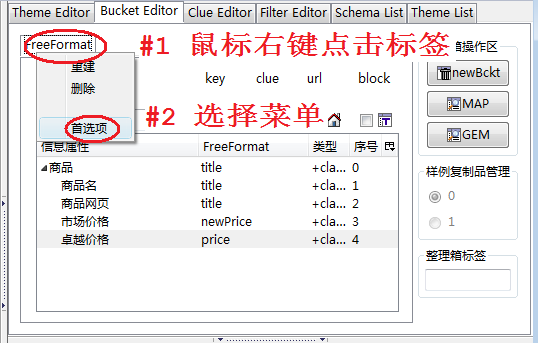
图8有如下步骤:
- 在Bucket Editor工作台的整理箱tab标签上点击鼠标右键,弹出菜单
- 选择菜单项首选项,弹出一个窗口,DOM节点定位由偏好id改成偏好class
再次生成抓取规则,这次就能够将所有商品信息抓取下来了,因为网页上很多DOM节点拥有共同的class值,如果使用class值作为FreeFormat标志,就能抓取多实例。
上载信息结构后,再转去Theme List工作台看主题的状态,第二级主题状态也变成了ready
4 下一步做什么
两级抓取规则定义完成后,就可以用DataScraper进行数据抓取了。既可以用DataScraper的手工批量抓取功能一级一级地启动抓取过程;也可以用周期性自动抓取功能自动启动抓取,而且可以将两级抓取放在两个不同的线程中并行抓取,甚至因为第二级数据比较多从而启动更多个线程或分布在多台计算机上。用户对两级抓取可能一开始理解的不正确,请注意:DataScraper并不能自动从第一级导航到第二级,而是像搜索引擎的网络爬虫一样同等对待这两级,所以这两个可以并行在两个线程中分别抓取。请注意阅读本文后面的讨论。详细说明参见《抓取当当网百货价格》。
卓越网上面商品类别很多,上文仅仅讲解手机类别的两级抓取,其它类别的数据抓取规则定义是否也这样从头做起?当然存在快捷方式:
- 方案1:采用图1C的方案,从一个总入口开始,先抓取大类别,然后抓取小类别,然后更小类别,直到商品详细信息网页。这是普通的网络爬虫模式,采用这种方式自动化程度高,按照本文一级级定义抓取规则即可。
- 方案2:采用图1A的方案,采用套用模板功能为其它类别定义抓取规则。这种方式自动化程度不高,但是,可以人工筛选商品类别。卓越网上同一个商品发布在多个不同类别中,而且这种重复现象大量存在,所以,手工选择类别可以大大降少抓取工作量。下一篇文章将讲解套用模板功能。
- Login to post comments
粤ICP备11065265号-2

Comments
DataScraper怎么显示出自己创建的主题
DataScraper没有能够显示之前自己创建的主题
你好
你好,有没有案例图1B的教程啊,我定义第一步规则采集到了各商品的url,但是没有生成第二步的,没有填写具体商品信息内容采集规则的任务
第二级只能抓取第一个类别的数据,其它类别的没有
fuller好,
我以京东大家电为例进行实践.
刚开始,我对每一个二级类别没有进行翻页抓取,这样可以获取所有二级类别的第一页数据.
后来我尝试对每一个二级类别进行翻页抓取,设置完成后,我却只能翻页抓取第一个二级类别的数据.
其它类别的数据就无法抓取了,请fuller看下错在哪里了.
谢谢fuller!
第一级主题:sere_category_JD
第二级主题:sere_list_JD
线索用完了要重新激活
比如,重新运行第一级,就能为第二级生成线索。或者,用crontab.xml中的指令激活
如何抓取所有类别下面各自的商品信息?
这个实例中分两层:
1. 抓取了所有类别;
2. 抓取了某一类别下的商品信息。
定义第二级的抓取规则时,在Theme Editor中要输入一个二级页面地址,结果必然是只能抓取某一类别下的商品信息。如果我要抓取所有类别下各自商品信息,需要一一对每个类别的定义第二级的抓取规则然后分别抓取吗?
定义规则是针对样本页面做的
定义规则是针对样本页面做的,不是说只对这个样本页面有效,抓取规则对这个主题的所有线索都有效。
执行第一级抓取的时候,相当于是说抓到的所有类别的网页都用第二级主题来抓取,所以,您不用担心您提出的那个问题
抓取第二层时出现页面的跳转
我是从百度百科中抽取植物这一大类。设置的是 孢子植物 和孢子植物二层 这两层,但是在抽取第二层时,每次大约抽取10个左右的页面后,datascraperr系统中浏览器就出现了百度首页的界面,但是我的规则从来没有定义到百度首页中。在datascraper的日志中出现了“suitable data schema cannot be found clueid 88273494 in 0st inthread cycle”这种字样。
百度百科抽取问题
我检查了这第一个信息结构,没有问题。会不会是以前曾经为第二层生成过线索?
每次10个左右,这个数字也比较特别,因为搜索结果网页上刚好有10个结果。你可以数数最后成功抓取了多少个第二层线索,百度的搜索结果显示有425个,看看能否对上
我试了其他的网站都可以,但是就百度百科的不行
我按照同样的方法提取京东上的信息,最后是成功的。没有出现类似的问题。是不是因为百度百科上我设置了block,我在京东上没有提取大段的文字信息的缘故。但我觉得应该不是block的问题。到底为什么百度百科上抽取大段文字信息时不能正常抽取第二层呀。
我试了好几次都不行,请你在帮我看看
你好,我想在和你说下我的问题。我的第一层没有问题,能够抽取下来,但是第二层就不行,开始时抽取正常,但是抽取几个页面之后就不能抽取了,跑到其他的页面上了这时datascraper浏览器中显示的页面也不是我想抽取的页面l了。我给你发了邮件,里面有错误信息的图片,希望你能帮助我
加载第二级样本页面后显示加载的页面不是工作页面
我在theme list工作台中单击右键选择识别后,样本页面加载上了,也刷新了DOM树,但是系统顶端变成了红色,显示当前加载的页面不是工作页面,相应的抓取规则也映射不成功。怎样解决不是工作页面这个问题?
我自己解决了
这个问题我已经解决了
怎么解决的?
我也只能提取二层的第一个页面
网站自身有一个延迟显示,无法抓取全部数据,怎么办
我在抓取http://hk.deals.yahoo.com/hong-kong/category/dinning雅虎团购数据时,该网站的网页使用了动态显示的方法,只有当屏幕向下滚动时才会逐渐显示全部内容。我在抓取第一层时Map-test时工作台能够输出全部内容,但是从datascraper从重新提取,就只能提取一小部分数据,我该如何是好?
设置自动滚屏嘛
datascraper有自动滚屏的参数选项的,教程里也有讲解自动滚屏的,去看看吧
关于抓取商品详情后,xml文件合并的问题
我在第一级主题(yesky_test)中抓取了列表和指向产品详情的url之后按照上文介绍的方法 添加url线索 定义了另一个主题(yeskey_detail),用于抓取商品具体详情。
商品列表采取分页抓取,每页20个商品,一共10页,然后用DataScraper 抓取yeskey_detail商品详情 发现生成的的xml文件 200个,每个商品详情占用一个xml,想把每个商品详情都存放在一个xml文件里; 怎么解决xml的数据合并问题,是不是我抓取方示不对?
抓取结果文件合并方法
DataScraper抓取网页时,每个网页生成一个XML文件,如果需要合并,则需要自己编写程序。如果是比较复杂的而且数据量很大的项目,可以购买配套的数据入库和清洗软件,这个软件可以与DataScraper配套,自动将抓取结果存入数据库,而且在存入过程中,根据规则进行数据清洗和转换,最后还可以导出成各种格式的文件。
可以更改第二步默认的样本页么?
我进行完第一步。为第二步抓取建立了许多线索。可是我识别后添加的默认样本页面里的内容是不完整的。无法让我完成映射。我想换一个内容完整的页面来作样本页面。可是我直接换URL 再映射就提示我位置已经改变了。 请问我如何才能更改默认的样本页。或者还有什么其他的解决方法?
换了样本页面后需要分析页面
MetaStudio的菜单"文件"->"分析页面",然后再映射就不会有问题了
第二级样本页一旦换成其他的就不能用了
之前觉得第二级制定采集规则默认加载的页面信息不全,就换了一个定义了,但是不成功,抓取的时候就什么也抓不到了,换的页面是不是必须得是第一级中采集到的网址中的其中一个啊
样本页面任意选择,要有代表性
样本页面要有代表性,应该选择一个内容更丰富的,但是要有代表性,网页结构确实是属于这一类网页,只要大家网页结构一样,针对一个样本页面定义规则就能适用于其它网页
信息属性list无法进行映射
在学习这个教程中,在第一步“抓取商品类别”的过程中,我设置了一个Freeformat“category”,然后照着指示,创建“list”包容在“category”中,当我希望将list和对应的节点的映射建立起来,系统却提示“Info: No FreeFormat available”,请问这是哪里出错了呢?
没有重现这个问题
我照着你的描述重做了一遍,没有遇到这个问题,能否将步骤说得更清楚一些,比如,第一步做什么;第二步做什么;到哪一步出现上述问题。这样我好定位
请问如何使用DataScraper抓取第二级网页?具体的操作方法?
我在第一级主题(yesky_test)中抓取了列表和指向产品详情的url;
之后按照上文介绍的方法 添加url线索 定义了另一个主题(yeskey_detail),用于抓取详情。
规则定义好了,请问如何使用DataScraper来启动抓取呢?如何在抓取时把这2个主题联系起来?我提取yesky_test这个,仍然只是有产品列表的数据。
是否需要配置什么文件?
谢谢
两层主题分别抓取
无论定义多少级,每个主题抓取时是互不相关的,但是抓取时最好先第一级,再第二级,不然的话,先抓第二级可能没有线索可用。具体操作方法参看《DataScraper批量抓取方法》。如果像本教材所说的要建立一个比价系统,应该采用教材中介绍的周期性自动化抓取方法,将抓取调度指令放在crontab.xml中。例如:
<crontab> <thread name="JD"> <parameter> <auto>true</auto> <start>5</start> <period>3600</period> <waitOnload>false</waitOnload> </parameter> <step name="renewClue"> <theme>demo_JY_mobile_category</theme> </step> <step name="crawl"> <theme>demo_JY_mobile_category</theme> <updateClue>true</updateClue> <dupRatio>100</dupRatio> <depth>-1</depth> <width>-1</width> <renew>false</renew> <period>0</period> </step> <step name="crawl"> <theme>demo_JY_mobile_list</theme> <updateClue>true</updateClue> <dupRatio>100</dupRatio> <depth>-1</depth> <width>-1</width> <renew>false</renew> <period>0</period> </step> </thread> </crontab>crontab.xml文件存放位置
请问,这个文件是存放在什么位置?是用户自己创建的吗?
crontab.xml要手工创建
手工创建后存放在.datascraper目录下。最好用Firefox打开看看有没有错误提示,如果所用的编辑器不是用来编程的,有可能会引入非法字符,Firefox能够检查出来
用于第二层抓取的线索重复
按这个例子写出来,抓取到的第二层结果文件有时候会重复。比如应该是6个子类型商品界面用于第二层抓取,但是结果得到的线索总数是14。就是说线索会重复。网速快的时候好像就不会有重复。
抓取卓越亚马逊和国美网上商城的注意事项
卓越亚马逊,国美网上商城,还有更多电子商务网站的URL地址有很多参数,即使参数不同,网页显示的内容是相同的。通常,比较关注搜索引擎优化(SEO)的网站不会出现这类情况,因为重复内容是不够优化的,但是,很多电商网站、社交网站、视频网站也许并不依赖于搜索引擎。另一方面,MetaSeeker并不遵照搜索引擎的友好性原则,不会依照网站的robots.txt规定的范围,MetaSeeker软件为了采集有价值的信息,具有更强的“狼性”,这样,robots.txt中规定的一些SEO规则会被忽略,会采集到很多重复网页,他们的内容相同,但是网址不同或者URL参数不同。
在处理采集结果的时候需要将重复内容过滤掉。
关于网速快慢对采集结果的影响我们没有观察到,也许会有这种可能,某些网站根据网速调整网页上显示的内容
fuller,你好: 批量抓取
fuller,你好:
批量抓取中使用的marker类型线索,教材中说明的很清楚,这个很明白。我的问题是:对于生成的info线索(指定了其新页面的抓取规则),这2个主题是如何联系起来呢?
比如:主题a是产品列表页的抓取主题,在其中定义了marker线索(用来翻页抓取),又定义了info线索(用来链接到具体的产品页,用于抓取具体的产品信息)。
主题b是定义的具体产品页的抓取规则。
那么具体操作如何做呢?使用DataScraper的批量抓取方法,只是抓取的列表页,没有关于产品详情页
抓取结果关联方法
将第一层和第二层的抓取结果文件打开看看就会发现:第一层文件的内容有产品详情页的网址,第二层文件的头部也有详情页的网址。两个匹配在一起就可以了。
根据详情页的网址进行关联
上面我给的crontab.xml例子就是抓两层的,两个主题在同一个线程(thread)中按顺序抓取,放在两个step中。
你定义的用于翻页的marker类线索因为指定为线内线索类型,只有这种类型会一口气导航抓取到底。其它非线内线索类型(例如本例的info类型)都需要另行安排DataScraper进行抓取。抓取第一层的时候只是将第二层的线索保存了下来,不会自动导航到第二层。上面给的crontab.xml是将两层放在同一个线程中顺序抓取,也可以放在不同线程中并行抓取。如果采用手工方法,则在DataScraper主题列表中先找到第一层主题,执行抓取,再找到第二层主题,进行抓取,抓取前应该先查询一下有多少可用线索,然后输入一个合适的数字。
关于第二层翻页抓取的问题
想咨询一下,我通过线索进入到第二层抓取的时候,由于第二层又是一个分页抓取的,我在第二层规则中按翻页抓取的规则进行定义,但就是无法抓取到第二层第二页以后的内容,不知该如何抓取?
我在第二层翻页规则中,采取的像当当网的方式,把翻页区作为线索,把“下一页”作为标记节点。
要看具体的信息结构
主题名是什么?我们可以一起分析一下
我也遇到了同样的问题
在二级抓取过程中设置了类似当当的线索,但还是不能翻页。
一级主题:demo_JY_category2
二级主题:demo_JY_list2
卓越网用了一些AJAX技术
参照demo_JY_list_1试试,看本手册关于AJAX抓取的章节
谢谢
问题解决了