翻页抓取当当网价格数据
本文是《定义网站抓取规则》一文的续文,那篇文章讲解了怎样用MetaStudio定义规则,而且不用编程,也不用察看网页的HTML代码,只需要鼠标点击并对被抓取的内容进行标注,抓取规则由MetaStudio自动生成。而且,我们还看到:在MetaStudio的抓取结果输出窗口中已经显示了网站抓取结果。但是,我们抓取当当网商品价格数据的目的是建立比价系统,如果从MetaStudio的抓取结果窗口中手工将结果数据拷贝出来显然是不符合自动化处理要求的,本文要解决以下问题:
- 翻页抓取所有商品信息
- 自动保存抓取结果
- 周期性自动化和增量抓取
1 定义翻页抓取规则
紧接着《定义网站抓取规则》的操作步骤,但是,这一次我们修改一下主题名以示区别:
- 主题名:demo_DD_list_1
注:本文定义的信息结构已经上载到服务器了,读者可以按照《加载信息结构》讲述的方法加载这个信息结构,以提高阅读本文的效果。
注意1:目标网页结构改变后可能会影响以前定义好的信息结构,如果加载不成功,可以参照《修改失效的抓取规则》一文对信息结构进行修改。
注意2:如果该信息结构加载不成功,可能还有别的原因,《抓取网页文字内容片断》给出了详细分析
假设我们已经按照《定义网站抓取规则》的操作步骤定义了当当网商品价格抓取规则,因为GSM手机有很多,分成了多页,接下来我们想翻页抓取每一页上的手机数据。当我们浏览网页并翻页时,我们需要点击一个表示“下一页”的超链接或者按钮,导航到下一页,GooSeeker(MetaSeeker的开发团队)称这个超链接或者按钮为线索,就是网络爬虫导航爬行的线索。线索有很多种,本文只用到记号线索,其它类型参见《获取网站抓取线索》。
1.1 创建线索
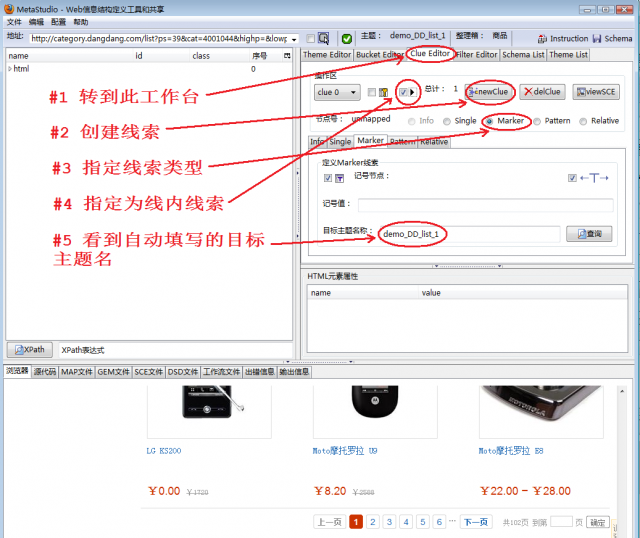
图1显示了怎样创建一个用于翻页的线索,有如下步骤:
- 转到Clue Editor工作台
- 点击newClue按钮,创建一个线索
- 点击Marker类型,设定为记号线索,“下一页”字样就是记号
- 指定为线内线索类型。
- 由于采用线内线索,目标主题名被自动填入,而且目标主题名与本主题名相同,可以手工修改目标主题名,但是,翻页抓取时不应该修改。什么时候修改?参见《抓取AJAX网站》教程。
翻页抓取时,导航到下一页的线索一般定义成线内线索,代表“下一页”的网页网址就不会被记录下来,只是临时用来翻页,这样可以大大提高抓取速度。如果记录下来还有个坏处:做价格跟踪监测时需要每天重复抓取所有商品价格,每次都从第一页往下翻页可以确保不遗漏也不重复。如果记录了中间页的网址,那么,重复抓取时有的从第一页开始翻页,有的从第N页开始翻页,存在大量重复。
什么时候不使用线内线索,参见《分级抓取》教程。
1.2 线索映射
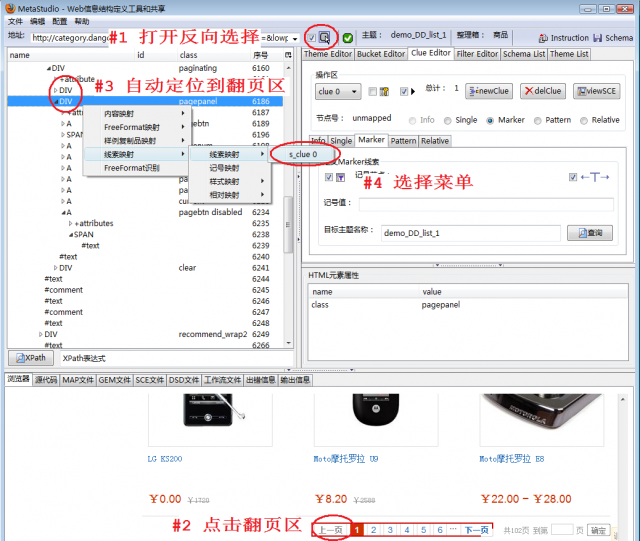
图2显示了线索映射过程,也就是告诉MetaStudio从哪里抓取超链接的URL地址。有如下步骤:
- 打开反向选择开关。参见《定义网站抓取规则》第三步。
- 在内嵌浏览器上点击翻页区
- 能够看到MetaStudio自动找到了翻页区的DOM节点,您需要找到代表整个翻页区块的那个DOM节点:@class=pagepanel的那个DIV
- 在DOM视窗中点击鼠标右键,选择线索映射菜单。详细说明参见《定义超链接抓取规则》
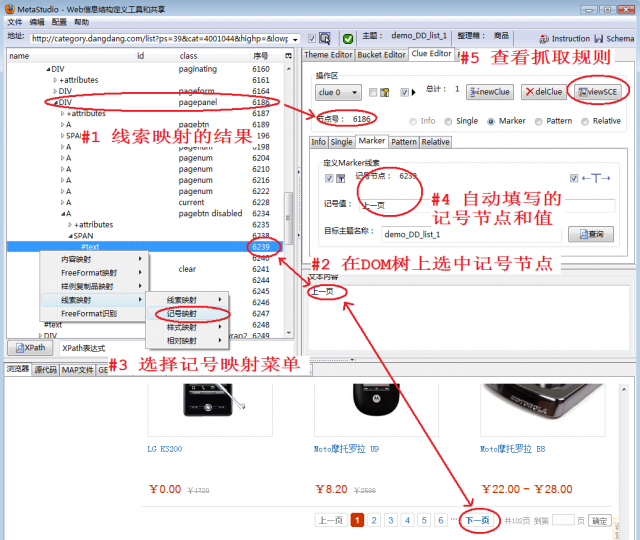
图3显示怎样映射记号,有如下步骤:
- 经过图2的步骤,可以看到线索映射的结果
- 在DOM树上找到含有记号“下一页”的那个TEXT节点,并选中它
- 在DOM树视窗上点击鼠标右键,选择弹出菜单项记号映射
- MetaStudio会自动将记号节点号和记号值填入
- 点击viewSCE按钮可以在MetaStudio下部的SCE文件窗口中看到线索抓取规则。
1.3 保存抓取规则
同《定义抓取规则》教程一样,点击MetaStudio的工具条上的schema按钮将定义好的信息结构上载到服务器,以便能够随时随地使用MetaSeeker云计算抓取服务。
至此,一个完整的网站抓取规则定义完了,既抓取页面上所有商品信息,也翻页到后续所有网页抓取更多商品。下面讲解怎样使用这个抓取规则。
2 DataScraper批量抓取
假设已经成功安装了DataScraper(参考《安装网站抓取系统MetaSeeker》),启动方法与MetaStudio相同。
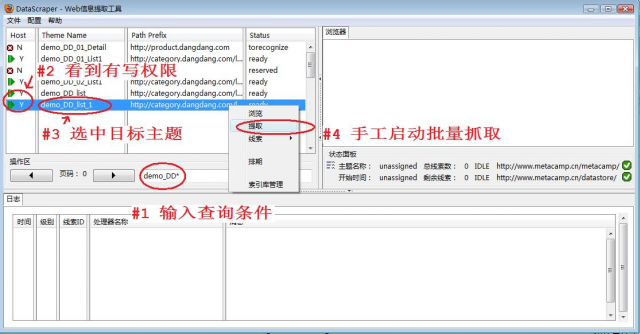
图4显示怎样手工启动批量抓取,有如下步骤:
- 输入查询条件,在主题列表中显示符合查询条件的主题名。可以使用通配符*,而且通配符可以出现多个。
- 绿色三角标志说明当前用户对这个主题拥有全部权限,能够执行抓取操作
- 选中主题demo_DD_list_1
- 在主题列表上点击鼠标右键,选择弹出菜单项提取,会弹出一个对话框,输入线索数量。本例在定义抓取规则时自动生成了一个线索,所以只能输入1,输入其它数字没有意义。
如图4,弹出菜单中有个菜单项“线索”-〉“统计”,用于查询可抓取的线索数,可抓取的线索是指处于start状态的线索。
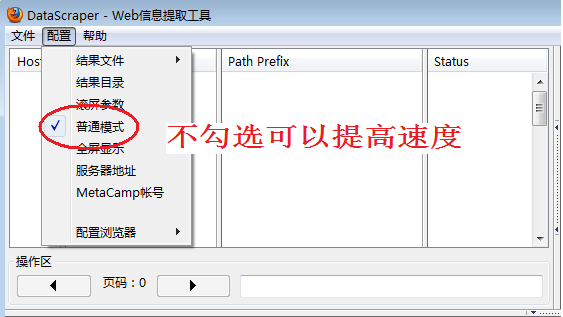
缺省情况下,DataScraper采用普通抓取模式,速度很慢,如图5所示,不勾选普通模式以提高速度。如果您购买了企业版,还有进一步提高速度的选项,参见《怎样提高采集京东商城商品价格的速度》。
3 文件存储目录结构
在线版MetaSeeker
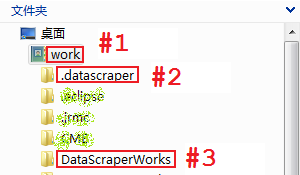
图6.a是一台运行MetaStudio和DataScraper的计算机的目录结构,当前Windows登录用户是work,几个主要的目录和文件是:
- work是当前Windows登录帐号,在这个目录下MetaStudio和DataScraper分别创建各自的配置文件:.metastudio.conf和.datascraper.conf,都是文本文件,可以编辑修改
- .datascraper是DataScraper创建的目录,用于存储日志文件和周期性自动抓取指令文件
- DataScraperWorks是DataScraper创建的目录,用于存储抓取结果,以主题名建立子目录,抓取结果是XML文件,存在各自的子目录下。
企业版MetaSeeker
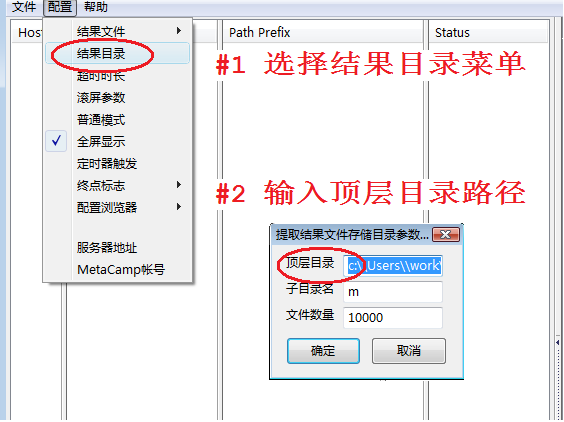
图6.b
企业版MetaSeeker的目录结构基本与在线版一样,但是,企业版用户可以选择存放位置,在线版将结果文件存放在当前登录用户目录下,在Windows操作系统上,一般存入系统盘上,因为系统盘空间有限,容易占满整个系统盘空间。图6.b显示企业版怎样指定结果文件存放位置,注意:在Window操作系统上,反斜线应该是双反斜线。
4 周期性自动化抓取
抓取当当网商品价格数据建立比价和价格跟踪系统时,需要定期重复抓取所有商品的价格,例如,每天抓取一遍,这需要配置周期性抓取指令文件,这是一个XML文件,存储在.datascraper目录下,名称是crontab.xml。里面可以配置的参数很多,例如,排期、是否增量抓取、批次大小、是否自动上载到服务器(需要安装配套的语料库管理系统MetaCorpora或者企业竞争情报系统SliceProfile)等等,需要研读 说明书。
使用周期性抓取指令文件还能够同时启动多个线程,同时对多个主题根据排期参数定时执行。
5 扩展阅读
下面的文章讲解了更多翻页抓取的技巧
- Login to post comments
粤ICP备11065265号-2

Comments
如何控制翻页的次数
设置完翻页抓取一般都是从第一页到最后一页吧,如果只想抓取前N页的数据怎么控制?
crontab.xml中的depth参数用于控制翻页次数
depth参数控制翻页次数
请问如何快速整合XML文件?我需要导入excel的,一个个导入太慢
请问如何快速整合XML文件?我需要导入excel的,一个个导入太慢
可以制作一个含有宏的excel模板
如果需要这个模板,请联系我们
网页抓取结果导成EXCEL格式
目前免费版本不提供导成EXCEL的功能,如需导出,可以与我们联系